One of the stranger structural shifts happening in AI infrastructure right now is that some of the most critical performance gains are no longer coming from raw processor speed. Instead, they are coming from a much more practical engineering discipline: avoiding redundant work.
While optimizing for redundant execution might sound like a minor software tweak, it has quickly become a defining architectural pillar for modern AI inference systems—especially as large language models (LLMs) continue to scale in context window size and structural complexity.
This is where Key-Value Caching (KV Cache) shifts from a niche software optimization into a foundational hardware requirement.
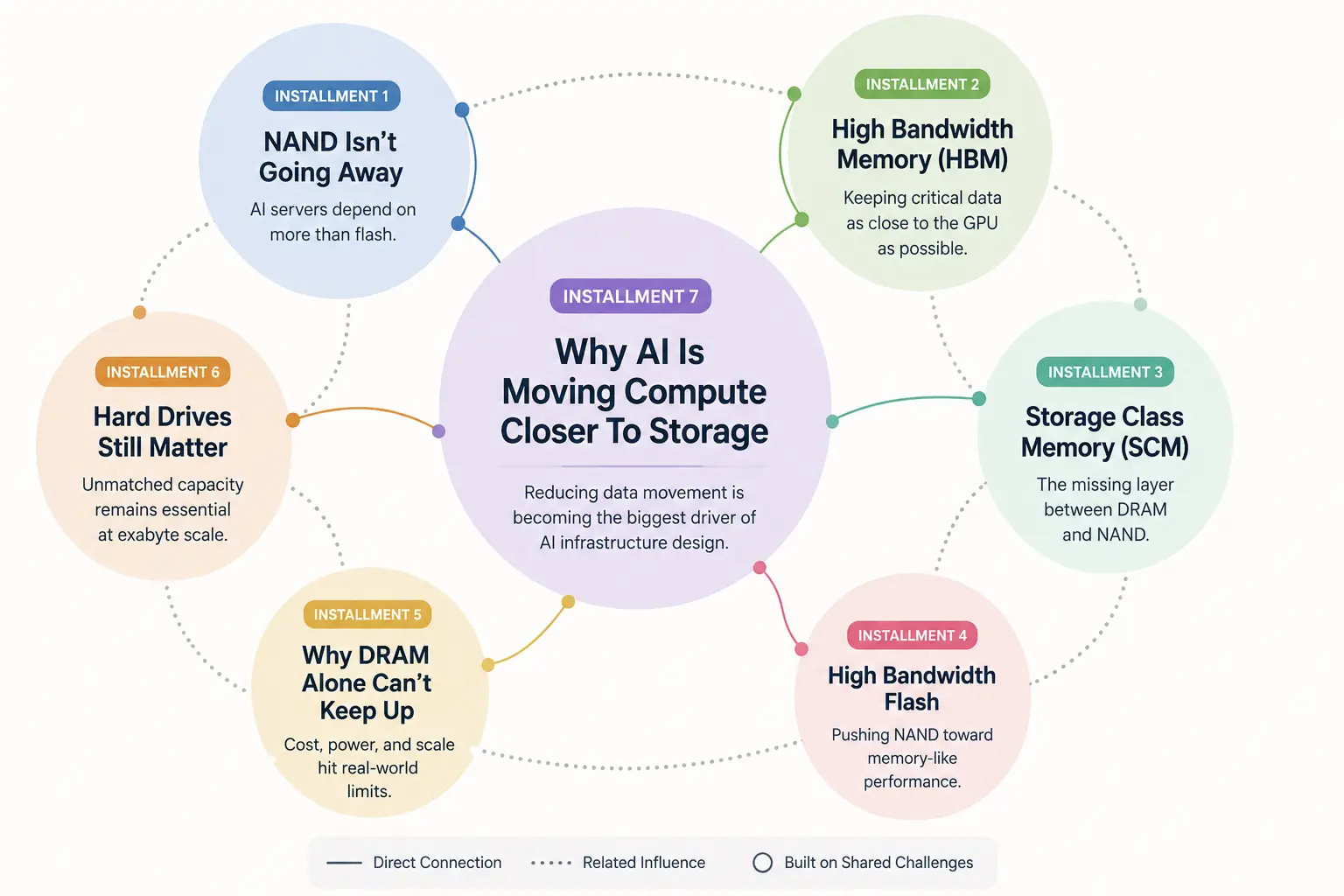
Throughout this ongoing series, we have analyzed how contemporary AI workloads are testing the limits of standard hardware design. We explored why servers can no longer rely on standard NAND flash alone, how High Bandwidth Memory (HBM) keeps data pipelines saturated, and where Storage Class Memory (SCM) bridges the architectural gap between DRAM and persistent storage. We have also covered the rising role of High Bandwidth Flash, the limitations of standalone DRAM, the persistent economic reality of hard drives at scale, and the industry-wide migration toward computational storage.
KV Cache serves as the invisible thread connecting all of these hardware layers. Because once an AI model reaches enterprise scale, the primary operational bottleneck is no longer just generating intelligence—it is remembering what has already been processed without repeatedly paying the massive computational tax of recalculating it.
What KV Cache Actually Is
At its core, KV Cache stands for Key-Value Cache. It is a specialized memory optimization technique designed to eliminate computational redundancy in transformer-based AI models.
To understand its function, consider how an LLM processes text. Every time a model evaluates a sequence, it maps out intricate internal relationships (attention weights) that dictate how words, phrases, and historical prompt context interact. In a standard stateless execution environment, recalculating these mathematical matrices for every single consecutive word would overwhelm both the GPU cores and the system’s available memory bandwidth.
KV Cache solves this by temporarily storing the “Keys” and “Values” of previously processed tokens in fast memory. By keeping these mathematical states intact, the model can instantly reuse them to generate the next token in a sequence rather than building the contextual history from scratch. In short, the system retains its mathematical train of thought as a conversation expands.
Shifting the Bottleneck from Compute to Flow Control
The growing reliance on KV Cache highlights a broader reality: modern AI systems no longer function as isolated, burst-heavy calculators. They operate as continuous data streams.
Every incoming prompt, generated token, and multi-turn agent workflow creates an ongoing fluid dynamic that the underlying hardware must manage in real time. While general tech coverage focuses heavily on the raw teraflops of a GPU, hardware deployment at scale tells a different story. Once inference workloads are distributed across millions of concurrent enterprise users, the engineering challenge shifts away from compute spikes and directly toward maintaining stable, uninterrupted memory flow.
In this environment, KV Cache functions less like static storage and more like an infrastructure traffic controller.
The Hydroelectric Dam Analogy
To visualize this dynamic, imagine a massive hydroelectric dam supplying power to a regional grid. The incoming river represents the continuous stream of user prompts and contextual tokens. The GPU serves as the heavy turbine system, converting that kinetic water flow into usable computational output.
Without a caching mechanism, the system would be forced to pump water all the way back upstream every time the grid requested an additional watt of power. Even with the world’s most efficient turbines, this constant, repetitive round-trip movement would introduce severe operational latency, massive power waste, and systemic instability.
KV Cache restructures this workflow by acting as a highly controlled reservoir positioned directly behind the turbines. Instead of forcing data back through the entire structural loop, the system keeps the most critical, immediate context ready for deployment.
This localized stability is vital because the rate at which data is fed into the compute engine dictates the efficiency of the entire rack. If the reservoir cannot supply data fast enough, expensive GPU architectures sit idle, waiting for memory cycles to catch up. The modern optimization problem is straightforward: AI platforms do not just need to think quickly; they need to remember quickly.
Why Massive Context Windows Strain the Memory Hierarchy
This architectural pressure accelerates dramatically as commercial context windows expand from a few thousand tokens to millions of tokens.
While a brief customer service chatbot interaction requires minimal active memory overhead, deep enterprise reasoning tasks—such as parsing massive legal repositories, analyzing entire software codebases, or running autonomous agents—fundamentally alter the math. Under these conditions, the required memory reservoir becomes immense, demanding that hardware preserve vast arrays of contextual data while maintaining sub-millisecond responses.
This is the exact inflection point where software caching algorithms collide with physical hardware constraints:
- HBM is required because the immediate GPU boundary demands unprecedented memory bandwidth.
- DRAM is deployed because active enterprise workloads require capacity pools larger than what HBM can economically scale to.
- Storage Class Memory (SCM) is introduced to smooth the physical latency gap between system DRAM and persistent flash layers.
- High Bandwidth Flash and high-capacity hard drives manage the underlying multi-terabyte training sets and archival data stores.
Because every single megabyte of cached contextual data introduces a direct trade-off between localized latency, hardware cost, and thermal power draw, the ultimate goal of modern AI engineering is shifting. The most efficient AI infrastructure of the next decade will not necessarily be the one that claims the highest theoretical compute ceiling; it will be the system built to minimize data movement and eliminate redundant calculations entirely.
AI Memory Infrastructure Series
This article is the eighth installment in our deep-dive series analyzing how enterprise AI workloads are reshaping modern memory, storage, and compute architectures. Read our previous installments for foundational context:
- Installment One:
NAND Isn’t Going Away, But AI Servers Now Depend on More Than Flash - Installment Two:
What Is High Bandwidth Memory (HBM) and Why AI Depends on It - Installment Three:
Storage Class Memory Explained: The Missing Layer Between DRAM and NAND - Installment Four:
High Bandwidth Flash: Can NAND Finally Act Like Memory? - Installment Five:
Why DRAM Alone Can’t Keep Up with AI Anymore - Installment Six:
Why Hard Drives Are Still Critical for AI Infrastructure - Installment Seven:
Why AI Is Moving Compute Closer To Storage - Installment Eight: KV Cache Explained: Why AI Memory Is Starting To Matter More Than Raw Compute
Let GetUSB.info keep you updated.
Receive article notifications about USB storage, flash memory, and duplication updates in your preferred language. We average a couple of articles per week.