For more than two decades, GetUSB has been covering how data actually moves, not just how it’s marketed. Over that time, we’ve watched storage evolve through a number of cycles, from the decline of spinning disks to the rise of flash, and more recently into systems where storage is no longer just a passive component, but part of the infrastructure itself.
What’s happening now with AI infrastructure feels like another one of those transition points, but with a different kind of pressure driving it.
NAND flash isn’t going away, and there’s no real argument there. It remains the foundation for modern storage, and it does that job extremely well. At the same time, demand for NAND has been climbing quickly, largely due to AI workloads that require enormous datasets and constant access to them. That demand is starting to push up against supply in ways that are becoming harder to ignore, whether that shows up as pricing pressure, tighter allocation, or simply longer lead times for large deployments.
When that kind of imbalance starts to show up, the industry doesn’t sit still and wait for things to normalize. It starts looking for other ways to solve the problem, and that’s where things begin to shift.
The Assumption Everyone Makes
If you look at it from the outside, the logic still seems pretty reasonable. AI models are getting larger, datasets continue to expand, and more infrastructure is being built to support it all, so the natural response is to add more storage. More SSDs, more capacity, more flash in the rack, and the system should be able to keep up.
That approach has worked for a long time, and in many environments it still does. The assumption behind it, though, is that storage behaves the same way under AI workloads as it did under more traditional ones, and that’s where things begin to drift.
It also assumes that NAND will continue to be available in the quantities needed, at predictable pricing, which is becoming less certain as demand accelerates.
Where NAND Starts to Show Its Limits
NAND flash is exceptionally good at what it was designed to do. It provides dense, reliable, and relatively fast storage, and for general-purpose computing it solved a long list of problems that existed with earlier technologies. Even today, for most workloads, it performs exactly as expected.
AI workloads, however, are asking for something slightly different, and that difference matters more than it might seem at first.
Instead of simply storing data and retrieving it when needed, these systems require a steady, continuous flow of data into highly parallel compute resources, often at speeds that are difficult to maintain consistently with traditional storage architectures. High-performance SSDs can handle bursts of activity and large queues of transactions, but feeding thousands of GPU cores in real time is a different kind of demand altogether.
At the same time, the underlying media – NAND itself – is becoming more expensive and, in some cases, harder to secure in large volumes. So now the industry is dealing with two pressures at once: the need for higher and more consistent data throughput, and the reality that the primary medium used to deliver that data is under supply and cost pressure.
That combination is what’s driving the current shift. Not because NAND has stopped working, but because relying on it alone is no longer enough to keep pace with what AI systems are trying to do.
The Industry Didn’t Replace NAND – It Built Around It
What’s starting to happen across AI infrastructure isn’t a clean replacement of NAND, and it’s not some sudden shift where flash disappears from the equation. If anything, NAND is still very much at the center of these systems. The difference is that it’s no longer expected to carry the entire load by itself.
Instead, the industry is building additional layers around it, each one designed to handle a specific part of the workload that NAND was never really meant to address on its own. In practice, that means rethinking how data moves through a system, where it sits at different stages, and how quickly it needs to be accessed depending on what the compute side is doing.
This is where the idea of a memory stack starts to show up more often. Not as a marketing term, but as a practical way to describe what’s actually being deployed. Rather than treating storage and memory as two separate categories, AI systems are starting to blur that line, creating multiple tiers that behave differently depending on speed, cost, and proximity to the processor.
NAND still plays a critical role in that stack, especially for capacity, but it now sits alongside other technologies that are designed to handle the parts of the workload where latency and bandwidth matter more than raw storage volume.
What’s Being Built Around NAND
Once you look at the system this way, the changes start to make more sense. Instead of trying to force NAND to do everything, the industry is introducing other layers that each solve a specific problem. Some of these are already in production, others are still evolving, but together they form the structure that modern AI servers are beginning to rely on.
Over the next set of articles, we’ll go deeper into each of these layers on its own, because each one deserves more space than a pillar article can reasonably give it. For now, the goal is to show how the pieces fit together so this article can stand on its own while also setting up the deeper dives to come.
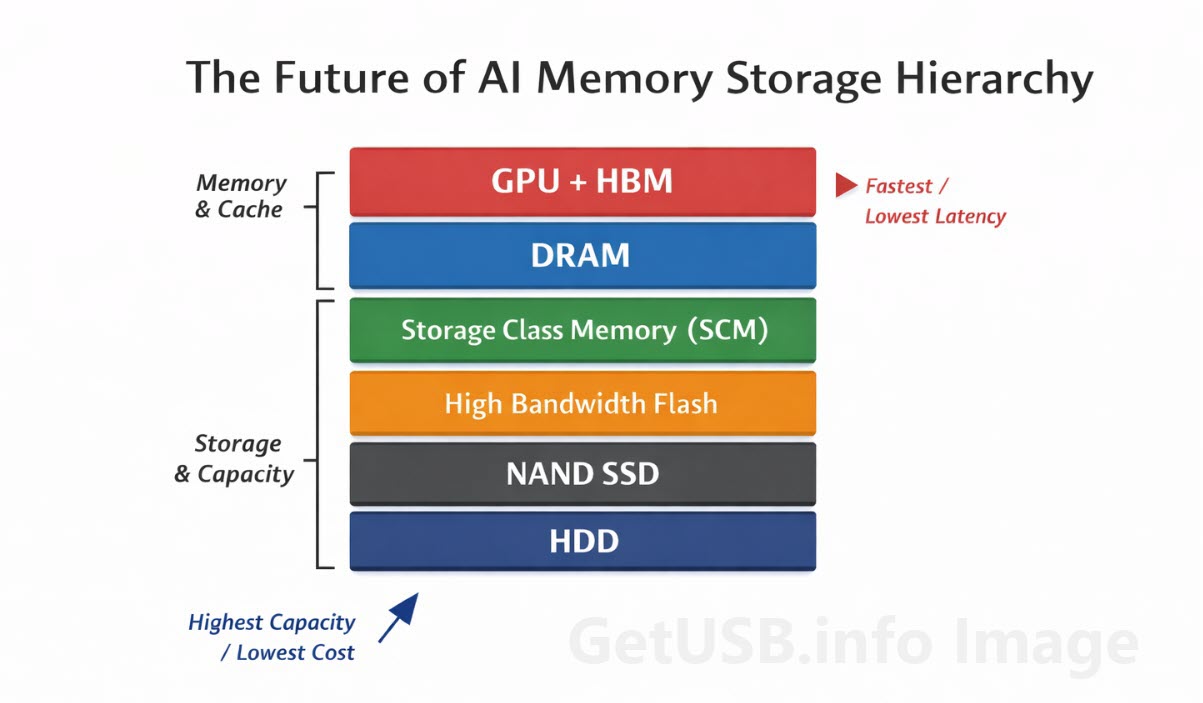
High Bandwidth Memory (HBM)
At the very top of the stack, closest to the GPU, is High Bandwidth Memory, or HBM. This is a type of stacked DRAM that sits physically near the processor and is designed to deliver extremely high data throughput with very low latency. It’s not a storage device in the traditional sense, but rather a specialized form of memory built specifically to keep modern GPUs fed with data at the rate they require.
HBM isn’t about capacity. It’s about keeping the GPU busy, which in AI systems is often the most expensive component in the rack. If that processor is waiting on data, everything behind it becomes less efficient. HBM addresses that by prioritizing bandwidth and proximity over size.
If you think about it in warehouse terms, HBM is like having the next pallet of product already sitting right at the loading dock with the wrapping off and ready to move. You’re not increasing how much inventory the warehouse holds overall, but you are making sure the forklift never has to stop and wait for the next load to arrive.
For a deeper look at how HBM compares to emerging alternatives, we’ve covered that here:HBM vs HBF: Why the Memory Hierarchy is Being Stretched
Storage Class Memory (SCM)
Just below that sits a category that didn’t really exist in a practical sense a few years ago: storage that behaves more like memory.
Storage Class Memory, or SCM, fills the gap between DRAM and NAND. It doesn’t have the speed of true memory, and it doesn’t have the density of flash, but it offers a balance that makes it useful for workloads that need faster access than NAND can provide without paying the full cost of DRAM at scale.
In AI environments, this kind of middle layer helps absorb some of the pressure that would otherwise fall directly on NAND, especially when dealing with large working datasets that don’t fit neatly into traditional memory.
The easiest warehouse analogy is to think of SCM as the staging area between the main warehouse shelves and the loading dock. The warehouse itself may hold everything, but it’s too slow to keep running back into the aisles every time a truck needs another box. The dock is fast, but space is limited. SCM is the in-between area where the most likely next shipments are stacked and ready, so the operation keeps moving without trying to turn the loading dock into the whole warehouse.
High Bandwidth Flash
This is where things start to get particularly interesting, because instead of introducing a completely different type of memory, the industry is also looking at ways to push NAND itself into new territory.
High Bandwidth Flash is an attempt to make flash behave less like a traditional storage device and more like an extension of memory. The goal isn’t to replace NAND, but to change how it’s accessed and integrated so that it can deliver data more efficiently to the layers above it.
In a way, this is NAND adapting to the new environment rather than being replaced by it, which aligns with what we’ve seen in previous transitions. Technologies rarely disappear overnight; they evolve to stay relevant.
DRAM and Its Limits
DRAM still plays a central role in all of this, and it’s not going anywhere either. It remains the primary working memory for most systems, including AI servers, and it handles a large portion of the active data that needs to be accessed quickly.
At the same time, scaling DRAM indefinitely isn’t practical. Cost, power consumption, and physical constraints all come into play, especially as systems grow larger. As a result, DRAM alone can’t absorb all of the additional demand created by AI workloads, which is part of the reason these other layers are being introduced.
In warehouse terms, DRAM is like the loading dock floor itself. It’s where the active work happens, where cartons are opened, sorted, and moved into the next step as quickly as possible. The problem is that there’s only so much dock space you can build before the cost, power, and layout stop making sense. At some point, you still need nearby staging zones and deeper storage behind them, because trying to do the entire operation on the dock alone becomes expensive and inefficient.
The Quiet Return of Hard Drives
Even with all the focus on high-speed memory and flash, traditional hard drives are still part of the picture, particularly at the lower end of the stack where cost per terabyte matters more than speed.
AI systems generate and consume massive amounts of data, and not all of it needs to sit in high-performance storage. Training datasets, archives, and less frequently accessed information still need a place to live, and for that, hard drives remain one of the most economical options available.
They don’t compete with NAND or memory on performance, but they reduce the overall pressure on those layers by handling the bulk storage requirements.
Moving Compute Closer to Storage
Another shift that’s gaining attention is the idea of reducing how far data needs to travel in the first place. Instead of constantly moving large amounts of data back and forth between storage and compute, some architectures are starting to bring processing closer to where the data resides.
This approach doesn’t eliminate the need for fast memory or storage, but it changes the balance. By handling certain operations closer to the data, systems can reduce bottlenecks and improve overall efficiency without relying entirely on faster media.
The Role of AI Context (KV Cache)
One of the less obvious factors driving all of this is the amount of temporary data AI models generate while they run. This is often referred to as context or KV cache, and it represents the working state of a model as it processes inputs and generates outputs.
That data doesn’t always fit neatly into traditional memory, especially at scale, which is why systems are starting to treat storage as an extension of memory rather than a completely separate layer. It’s another example of how the boundaries between these categories are becoming less defined.
A warehouse analogy works here too. KV cache is like the running clipboard and active pick list for everything currently being packed, sorted, and shipped. It isn’t the full inventory, and it isn’t long-term storage, but if that live working record gets too large or too hard to access, the whole operation slows down because nobody knows what was just picked, what comes next, or where the current order stands.
The New AI Memory Stack
When you step back and look at the system as a whole, it starts to resemble a layered structure rather than a simple hierarchy.
At the top, you have the GPU paired with HBM, handling immediate, high-speed operations. Just behind that sits DRAM, managing active workloads that require quick access but don’t need to be directly on the processor. Below that, emerging layers like SCM and high-bandwidth flash help bridge the gap between memory and storage, providing additional capacity without sacrificing too much performance.
Further down, traditional NAND continues to handle large-scale storage, while hard drives take on the role of long-term, cost-effective data retention.
If you picture the whole thing as a warehouse, the structure becomes easier to follow. HBM is the pallet waiting at the dock, DRAM is the dock floor where the active work happens, SCM is the staging area just behind it, NAND is the main warehouse shelving, and hard drives are the deeper bulk storage in the back where cost and capacity matter more than speed. The system works because each layer has a role, and because no one expects the far back of the warehouse to do the job of the loading dock.
Each layer serves a purpose, and together they form a system that is better suited to the demands of AI than any single technology could be on its own.
What This Means Going Forward
The takeaway here isn’t that NAND is being replaced, or that a single new technology is stepping in to take its place. What’s happening is more gradual and, in some ways, more interesting.
The industry is acknowledging that no single layer can handle everything, especially under the demands of AI. Instead of forcing one technology to stretch beyond its limits, it’s building a system where multiple layers work together, each optimized for a specific role.
That shift changes how we think about storage. It’s no longer just about capacity or even raw speed, but about how data moves through the system and how efficiently each layer supports the one above it.
And as these architectures continue to evolve, NAND remains a critical part of the picture – just no longer the only one.

